
Research on Relation Extraction with SVM and BERT
- 2025年11月12日
- 讀畢需時 8 分鐘
1 Introduction
Relation Extraction (RE) is a fundamental task in Natural Language Processing (NLP) that focuses on identifying semantic relationships be tween entities within a given sentence. It is a key component of various NLP applications, including information extraction, knowledge graph construction, and question answering systems (Bassignana & Plank, 2022). Over the years, research on relation extraction has evolved from early statistical and feature-based machine learning methods such as support vector machines (SVMs) to modern deep learning methods driven by pre-trained language models such as BERT, which utilize contextual representations to improve performance ((Devlin et al., 2019). In addition, some studies have explored hybrid techniques that combine traditional and deep learning models to leverage the strengths of each.
To advance RE research, various benchmark datasets have been developed to facilitate model evaluation and comparison. In this study, we adopt SemEval 2010 Task 8 as our experimental dataset (Hendrickx et al., 2010). This dataset is specifically designed for multi-way classification of semantic relations between entity pairs and contains manually annotated sentences la belled with 19 relation types, including additional categories for cases where no meaningful relations exist. It consists of 8,000 training samples and 2,717 test samples, making it a reliable dataset for evaluating RE models.
In this study, we developed and improved two different RE models based on the SemEval 2010 Task 8 dataset. The first is a hybrid SVM based model that integrates TF-IDF for text enhancement, BiLSTM with Attention for feature extraction (Zhou et al., 2016), and GloVe pre-trained word embeddings to enhance the mod el's understanding of semantic relations. The second is an improved BERT-based model, which employs contrastive learning (Gao et al., 2021) to make samples of the same class more tightly clustered and incorporates external knowledge from WordNet and Wikidata (Peters et al., 2019; Yao et al., 2019) to improve generalization.
To evaluate the effectiveness of the proposed methods, we use Precision, Recall, and F1-score as performance metrics. Precision measures the accuracy of classification, while Recall reflects the model's ability to capture correct relations. F1-score balances both metrics, providing a more comprehensive assessment of overall performance. Experimental results demonstrate that our approach significantly outperforms the baseline across multiple relation categories. Moreover, our analysis highlights the strengths and limitations of traditional machine learning methods (SVM) and deep learning approaches (BERT) in the RE task, providing a clearer understanding of their practical advantages and challenges.
The remainder of this paper is structured as fol lows: Section 2 reviews related work, Section 3 introduces the methodology, Section 4 presents results and discussion, and Section 5 concludes the study.
2 Review of Related Work
Relation Extraction (RE) has evolved from symbolic methods relying on hand-crafted rules to modern deep learning approaches. Early work employed rule-based systems and boot strapping techniques, but these suffered from limited adaptability (Bassignana & Plank, 2022). Traditional machine learning models, such as Support Vector Machines (SVMs), introduced feature engineering (Zhou et al., 2005; Hong, 2005). Kernel methods fur ther leveraged syntactic structures for improved performance (Zelenko et al., 2003). However, these approaches often struggled with complex sentence structures and long-range dependencies.
Deep learning methods addressed some of these challenges by automating feature extraction with RNNs, CNNs, and LSTMs (Zhang et al., 2015). BiLSTM-based models improved se quential encoding, and attention mechanisms helped capture long-distance information (Ni et al., 2021). Yet, these architectures sometimes lacked sufficient global context.
Transformer-based models, especially BERT, substantially advanced RE via self-attention and contextual embeddings (Wu & He, 2019; Thillaisundaram & Togia, 2019). For instance, R-BERT incorporated explicit entity information into BERT, demonstrating the importance of entity-level features in improving RE performance (Wu & He, 2019). Nonethe less, BERT-based models can struggle with semantically similar relations and often neglect external knowledge (Peters et al., 2019; Yao et al., 2019).
In our work, we address these gaps by combining SVM with BiLSTM-based feature extraction, and by augmenting BERT with external knowledge and contrastive learning. These refinements aim to improve semantic understanding, reduce confusion among closely related classes, and enhance overall RE performance.
3 Methodology
3.1 SVM-Based Method
SVM is effective in high-dimensional spaces and is widely used in RE tasks, attributed to its solid theoretical foundation (Cortes & Vapnik, 1995). However, to improve its feature representation, we integrate BiLSTM with Attention for encoding text sequences before classification. This approach allows the model to capture long-range dependencies that conventional feature-based methods often fail to model effectively.
The implementation follows a structured pipe line. First, we load the SemEval 2010 Task 8 dataset, extracting sentences as features and relations as labels. The initial SVM implementation uses CountVectorizer to transform the text into word frequency vectors before training the classifier. Earlier studies have combined SVM with kernel methods for relation extraction tasks, achieving promising results (Zelenko et al., 2003). However, this method was later improved by replacing CountVectorizer with TF-IDF vectorization, which provides more in formative word representations by reducing the influence of frequently occurring words.
The second improvement introduces BiLSTM with Attention for feature extraction. Text sequences are padded to a uniform length, then processed through a model consisting of an in put embedding layer, a BiLSTM layer for con textual encoding, an attention mechanism to emphasize key features, and a pooling layer for dimensionality reduction. The resulting embed dings are then passed to the SVM classifier.
Further enhancements include class weighting and GloVe embeddings to handle class imbalance and improve word representations. Since certain relation types appear less frequently in the dataset, class weighting adjusts the loss function to assign higher importance to underrepresented classes. Additionally, GloVe embeddings provide pre-trained word vectors, enriching the semantic representation of text.
3.2 BERT-Based Method
BERT is selected due to its ability to model con textual dependencies using self-attention mechanisms. However, traditional fine-tuning with a classification head struggle to distinguish semantically similar relations. To address this, we incorporate contrastive learning to enhance class separability and external knowledge integration to improve semantic understanding.
Unlike the SVM model, BERT requires a different pre-processing approach. The SemEval 2010 Task 8 dataset already contains and entity markers, but these need to be con verted into a format compatible with BERT. We explicitly tag entities using WordPiece tokenization, ensuring the model can effectively process relational information.
To further enhance the dataset, we integrate WordNet and Wikidata as external knowledge sources. WordNet definitions are retrieved and appended to the sentence, enriching its semantic context (Joachims, 1998). Additionally, Wiki data relations are extracted via SPARQL queries, providing structured relational information. We adopted a method similar to Li and Wu (2020), directly incorporating WordNet synsets and hypernym information into the model representation. The final augmented sentence includes entity definitions and knowledge graph relations, improving the model’s ability to differentiate relation types.
Example of transformed input: "The company acquired the startup. [SEP] company: A business organization [KG: owns: subsidiary]. [SEP] startup: A newly founded business entity [KG: funded by: investors]."
The processed text is tokenized using BERT’s WordPiece tokenizer and input into the BERT encoder. To further refine relation classification, we employ Supervised Contrastive Learning (SCL), which encourages representations of the same relation type to be closer while push ing apart different relation types (van den Oord et al., 2018). Instead of solely relying on cross entropy loss, contrastive loss is introduced to re shape the embedding space, making relations more distinguishable. To optimize training, we use a linear learning rate scheduler with AdamW optimizer. The CLS token representation is used for final classification, leveraging BERT’s pre-trained knowledge to improve RE performance.
4 Results and Discussion
This section presents the experimental results of the two relation extraction approaches studied in this work: SVM-based and BERT-based models. We analyze the performance of both methods, highlighting the impact of TF-IDF vectorization, BiLSTM + Attention feature ex traction, and external knowledge augmentation for SVM, as well as knowledge integration, contrastive learning, and learning rate scheduling for BERT. The models are evaluated using accuracy, precision, recall, and F1-score.
As shown in Figure A.1, The baseline SVM model achieved an accuracy of 53.77% and an F1-score of 46.06%, indicating challenges in relation classification. Its reliance on CountVec torizer-based frequency representations resulted in poor recall (42.77%), particularly for low-resource relation types such as Entity-Destination and Content-Container. The introduction of TF-IDF vectorization improved text representation, increasing accuracy, but long-distance dependencies remained an issue.
Further enhancement with BiLSTM + Attention allowed the model to capture sequential dependencies, leading to a performance boost (70.30% accuracy, 66.80% F1-score; Figure A.2). The most significant improvement came from external knowledge augmentation using GloVe embeddings, which enriched semantic representations. Despite these advancements, ambiguity in certain relations persisted, and the model’s performance was still inferior to deep learning-based approaches.
The baseline BERT model significantly outperformed SVM, achieving 76.11% accuracy and 71.24% F1-score, highlighting the advantage of self-attention and contextual word representations. However, it struggled with relations re quiring external knowledge and distinguishing semantically similar relations. To address these limitations, we integrated WordNet for entity level enhancement and Wikidata for relation level knowledge augmentation. WordNet pro vided entity definitions, improving entity disambiguation, while Wikidata offered structured knowledge, enhancing relation differentiation.
Supervised contrastive learning was introduced to refine the representation space, ensuring that similar relation types clustered together while dissimilar ones were pushed apart. This was particularly effective for semantically overlap ping relations, reducing misclassification be tween Cause-Effect and Instrument-Agency. Learning rate scheduling further stabilized training, preventing overfitting and improving generalization.
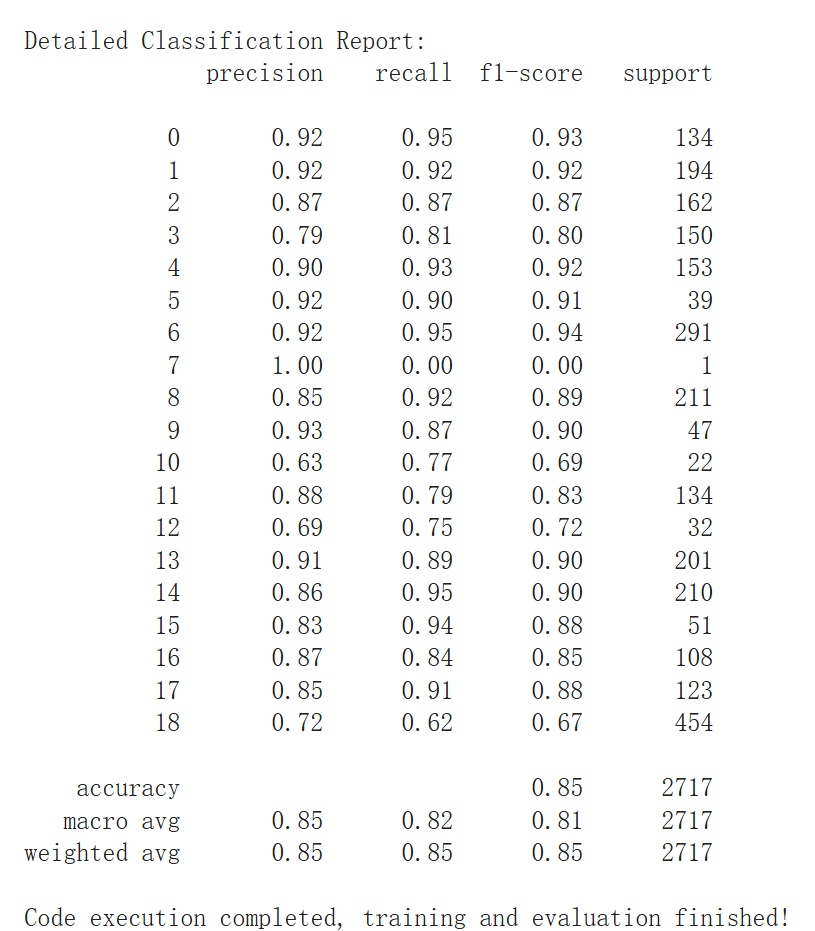
The final BERT model achieved an accuracy of 85.24% and an F1-score of 81.01%, a signifi cant improvement over the baseline BERT and SVM model. The macro-average recall in creased from 72.35% to 82.05%, confirming that external knowledge and contrastive learning improved model robustness. For a detailed visualization of these results, please see Figure B.1 and B.2
To compare traditional and deep learning-based approaches, the best SVM model (70.30% ac curacy, 66.80% F1-score) was contrasted with the final BERT model (85.24% accuracy, 81.01% F1-score). The SVM model struggled with contextual relationships and required manual feature extraction, whereas BERT automatically learned representations and benefited more from external knowledge augmentation. These results confirm the superiority of deep learning-based models for relation extraction, particularly in handling complex semantic relationships and context-dependent relations.
This study presents a comparative analysis of SVM enhanced with BiLSTM, and BERT enhanced with contrastive learning and knowledge augmentation. The SVM-based model is well-suited for low-resource settings, where structured feature extraction plays a crucial role. Meanwhile, the BERT model demonstrates superior performance in capturing complex relational contexts. By integrating external knowledge from WordNet and Wikidata, both approaches achieve improved semantic under standing, leading to enhanced RE performance.
5 Conclusion
This study demonstrates that relation extraction performance can be significantly enhanced through external knowledge integration, contrastive learning, and optimized training strategies. The SVM model, improved with TF-IDF, BiLSTM + Attention, and external knowledge embeddings, showed notable gains but remained limited by its reliance on manual feature extraction. In contrast, the BERT model, enhanced with WordNet, Wikidata, contrastive learning, and learning rate optimization, achieved 85.24% accuracy and 81.01% F1 score, outperforming both the baseline BERT and the best SVM model.
Despite improvements, challenges remain. Low-resource relation types still exhibit lower recall, and structured knowledge sources do not always provide sufficient coverage. Future work could explore dynamic knowledge retrieval for real-time knowledge integration and more advanced pre-trained models like DeBERTa or T5 to enhance contextual under standing.
These results confirm that transformer-based models, when optimized with knowledge augmentation and improved training strategies, out perform traditional machine learning methods in relation extraction. Future research should focus on scalable deep learning architectures and adaptive knowledge integration to further improve model robustness and generalization.
References
Conference on Language, Information and Computation (pp. 73-78). Association for Computational Linguistics. Bassignana, E., & Plank, B. (2022). What Do You Mean by Relation Extraction? A Survey on Datasets and Study on Scientific Relation Classification. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop (pp. 67-83). As sociation for Computational Linguistics.



留言