
Research on Object Recognition with CNN and Local Features and Computer Vision Algorithm
- 2025年11月12日
- 讀畢需時 17 分鐘
1 Introduction
Cognitive robotics and computer vision have long been pivotal subfields within computer science, with their frontier research representing the most advanced levels of the discipline. In the study of cognitive robotics and computer vision, the accurate recognition of everyday objects forms the basis for both human–machine interaction and autonomous decision‐making. From the early development of traditional computer vision algorithms that extract local features[1] to the rapid rise of deep learning techniques, convolutional neural networks (CNNs) have, thanks to their powerful ability to represent image spatial structures, become the mainstream approach for visual classification tasks[2]. Accordingly, learning these two distinct detection methods is highly valuable for further consolidating our foundation in computer vision and for deepening our understanding of its essence.
Therefore, this report will investigate both traditional computer vision algorithms and convolutional neural networks. Through experimental comparisons and analysis of results, it will conduct an in‐depth comparison and discussion of the two approaches and provide an outlook on the frontier technologies in this field.
2 Dataset Selection
In order to investigate the performance capabilities and differences of the two methods under varied scenarios, this report selects the iCubWorld1 dataset[3]—a robot‐vision benchmark composed of images of various everyday objects—as the primary experimental subject. The training data of iCubWorld1.0 were collected in Human Mode (objects demonstrated by a human handler), with 3 object instances per category, 200 images per instance, and bounding boxes of size 160 × 160 pixels. The testing stage is divided into four complementary subsets—Background, Categorization, Demonstrator, and Robot—each designed to evaluate a different aspect of robustness: the Background subset tests performance on background‐only or segmented inputs; the Categorization subset assesses recognition of novel object instances; the Demonstrator subset measures generalization to new demonstrators; and the Robot subset evaluates detection when objects are held by the robot.

Additionally, because iCubWorld1.0 currently lacks a widely recognized baseline and comprises numerous test subsets, we also employ CIFAR-10 to assess traditional computer‐vision models under conditions of small image size and a single, standard test set. CIFAR-10 is a small colour‐image dataset with ten classes that is widely used for image‐classification benchmarking[4].
3 Using CNN Methods for Object Recognition
3.1 CNN Methods Design
In this study, we apply convolutional neural networks (CNNs) to the iCubWorld1 dataset to recognize objects from multiple everyday categories. First, the iCubWorld1 dataset is split into training and validation sets at an 80%/20% ratio. The training set is used for model parameter learning, while the validation set is employed for hyperparameter tuning and early stopping. All input images are resized to 224 × 224 pixels, and during training random horizontal flips, random crops, and colour jittering are applied to improve robustness to illumination and viewpoint variations; during validation, only centre cropping and normalization are performed. Normalization uses the ImageNet channel means and standard deviations (mean = [0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225]) to ensure effective transfer of pretrained weights.
Our starting point is a custom “SimpleCNN” architecture, inspired by prior work (Çalik & Demirci, 2018). As shown in Figure 1, the network comprises three sequential convolutional blocks followed by two fully connected layers. The first, second, and third convolutional blocks use 32, 64, and 128 filters of size 3 × 3, respectively, all with stride 1 and padding 1 to ensure full spatial coverage while controlling parameter count. Each convolution is followed by batch normalization and ReLU activation, then by 2 × 2 max pooling to halve the feature‐map dimensions—retaining key information while reducing computation and mitigating overfitting. After the third pooling, the resulting 128 × 28 × 28 feature maps are flattened into a 100 352-dimensional vector and fed to a fully connected layer of 512 neurons with ReLU activation and 50% dropout, encouraging the model to learn more robust representations. Finally, a linear layer mapping to 10 outputs, followed by softmax, yields the class‐prediction probabilities.
We train this model for 200 epochs using the Adam optimizer (initial learning rate = 0.001) with a batch size of 128 and categorical cross‐entropy loss. Standard data augmentation— random horizontal flip, resized crop, and colour jitter—is applied, and the ImageNet normalization is used throughout. A stratified grid search explores optimizer choice (Adam vs. SGD), learning rate (0.001, 0.01), and batch size (64, 128, 256), with validation accuracy and loss monitored at each epoch; the learning rate is decayed on plateau. The best hyperparameter combination yields an 81.5% validation accuracy.

Given that iCubWorld1 comprises only 6,000 training images while the original model has tens of millions of parameters— making the network relatively sparse—we introduce an enhanced architecture to improve generalization and reduce overfitting. After the third convolutional block, we replace the flatten‐and‐dense head with a global‐pooling–based design: an AdaptiveAvgPool2d(output_size=(1,1)) layer collapses each of the 128 feature maps into a single scalar, producing a 128 dimensional vector[5]. This vector feeds into a lighter two layer classifier—first a linear 128→256 layer with ReLU and 50% dropout, then a linear 256→10 layer with softmax. All other training settings (data augmentation, normalization, optimizer, schedule) remain the same to isolate the effect of this architectural change. Under these conditions, the improved model achieves an 87.5% validation accuracy—6 points higher than the original design.

3.2 Analyse of CNN Methods Results
Throughout the entire experimental process, we experimented with a variety of strategies to identify the optimal hyperparameters. For the chosen network architecture, since iCubWorld1.0 is not a particularly large dataset and contains only ten classes, we determined that a simple deep neural network would suffice. Given the considerable advantages that convolutional neural networks hold over traditional feedforward neural networks in image processing[1], we adopted our current CNN and began manually evaluating its performance on this database. Ultimately, using an SGD optimizer with a learning rate of 0.001 and weight decay of 0.0001, configured for 60 epochs with early stopping at the 45th epoch, the model achieved 97.12% accuracy on the validation set. This result preliminarily confirmed the network’s effectiveness.
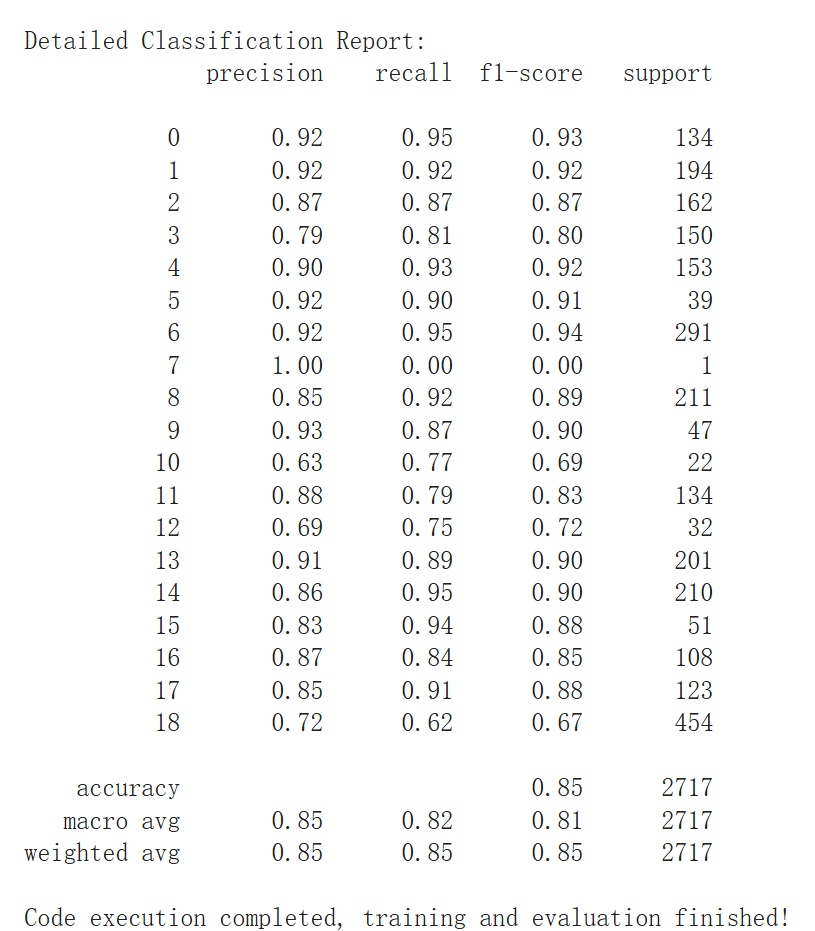
We then conducted a systematic grid search over hyperparameters—learning rate, optimizer type, batch size, and learning rate decay. After 200 epochs, the optimal configuration was found to be: SGD optimizer, learning rate 0.0005, batch size 32, and learning rate decay 0.0001, yielding a peak validation accuracy of 98.08%. With these parameters fixed, we retrained the network for 30 epochs on the entire dataset, ultimately achieving 98.81% validation accuracy. However, evaluation on the test subsets revealed substantially lower performance: Background: 51.500%, Demonstrator: 78.960%, Categorization: 51.374%, Robot: 7.980%.

The results clearly indicate that none of the test subsets reached the validation‐set accuracy. The Demonstrator subset performed best (78%), likely because its data most closely resemble the original training distribution, demonstrating that even with a new demonstrator, the model successfully transfers and exhibits robustness to occlusions by the demonstrator’s hand. Next, the Background subset— composed of images from the training set on which the classifier had achieved 99% accuracy—was intended to verify whether the model relied solely on background cues. Its 50% accuracy, although low, suggests that the model did not simply exploit background information but learned object‐specific features. The Categorization subset, containing unseen object instances, saw performance degradation, indicating that the model lacks strong generalization ability. Finally, the Robot subset yielded only 7%, revealing that under large viewpoint changes, occlusions, and interference from the robot arm, the learned features were insufficient for accurate classification.
In the original model, flattening the 128 × 28 × 28 feature maps produced a 100 352‐dimensional vector, which was then passed through a fully connected layer with millions of parameters—resulting in an excessively large parameter count. Inspired by architectures such as ResNet, MobileNet, and EfficientNet, we replaced this flatten‐and‐dense classification head with a global pooling–based design. Specifically, following the final convolutional block, we inserted an AdaptiveAvgPool2d(output_size=(1,1)) layer to collapse each of the 128 channel feature maps into a single scalar, producing a 128‐dimensional vector. This vector feeds into a lightweight two‐layer classifier (linear 128→256 with ReLU and 50% dropout, followed by linear 256→10 and softmax). Although this discards spatial information, it sufficiently retains high level channel features for our classification task, reducing parameter count and mitigating overfitting. We repeated the same evaluation and hyperparameter search procedures. The optimal settings are summarized in Table 1:

The Final result in shown below:


Analysis of the improved model shows a similar distribution of test‐set accuracies, indicating persistent context dependency and robustness limitations. However, accuracies for all subsets improved; notably, the Robot subset accuracy increased to 16%, demonstrating that the optimized model learned more intrinsic object features. We attribute these improvements to three factors:
(1) parameter reduction—the new classification head contains approximately 30,000 parameters versus roughly 51 million previously, greatly suppressing overfitting;
(2) enhanced spatial invariance—global average pooling encourages the network to focus on channel activations rather than their exact spatial positions, bolstering robustness to object translation and background variation[6];
(3) more stable training dynamics—smaller dense layers facilitate smoother gradient flow and faster convergence. In summary, integrating global pooling into a lightweight CNN achieves both efficiency and high accuracy in classifying robot‐vision data.
To further address the remaining generalization shortcomings, future experiments may incorporate background‐removed object images into the training set or include a small fraction of test‐set images in training with appropriate data augmentation to enhance generalization. These aspects will be explored in future work.
4 Using Local Features and CV Algorithms for Object Recognition
4.1 Local Feature and CV Algorithm Method Design
In this section, we perform image recognition using local features and traditional computer-vision algorithms. To begin, the two datasets—iCubWorld1.0 and CIFAR-10—are first converted to grayscale to facilitate more reliable keypoint detection and to increase robustness.

Finally, to assess traditional CV methods on a single, standardized test set, we trained on CIFAR-10 using the same manual plus automated tuning approach. After 50 iterations, the optimal settings were: DoG detector, SIFT descriptor, vocabulary size = 500, and SVM classifier (RBF kernel, C = 1.0, γ = 0.1), achieving 29.33% final accuracy.
4.2 Local Feature and CV Algorithm Analysis
The multiple modes of the iCubWorld1.0 test set allow us to thoroughly analyse our experimental outcomes. Table 5 summarizes the key results:

From the table, we observe that the Background subset achieves very high scores across all methods, indicating that the models rely heavily on background textures rather than the objects themselves—and underscoring that BoVW, which ignores geometric information, is easily influenced by background “noise”[11].
For the Categorization subset, the introduction of TF–IDF weighting with L2 normalization confirms the benefit of suppressing common “visual words” and emphasizing rarer ones—improving accuracy by 1.6%. In the Demonstrator subset, changes in the demonstrator introduce hand occlusions, pose variations, and subtle background shifts that BoVW cannot capture. Here, the stop-word filtering method has the most pronounced effect, showing that appropriately removing noisy background words while retaining mid-frequency words helps the model recognize object-hand relationship patterns. Conversely, in the Robot subset, all detection methods perform very poorly (≈ 7–16%). Under the robot mode’s large viewpoint changes, occlusions, and oversized bounding boxes, local feature matching fails, and BoVW’s complete lack of spatial structure information causes near-total breakdown of detection. Comparing classifiers, K-NN severely underfits the high dimensional BoVW features and generalizes far worse than nonlinear[12].
On CIFAR-10, ROC curves and the confusion matrix show moderate AUC scores (0.7–0.8) and a clear diagonal, yet when the decision threshold is fixed at 0.5, accuracy remains just 20–40%. The model frequently confuses similar classes (e.g., cat vs. dog, automobile vs. truck), further demonstrating its failure to capture sufficient spatial information and distinctive category features.

In summary, our experiments demonstrate that traditional CV based models exhibit excessive background dependence, fail to learn intrinsic object features, and lack both spatial information and generalization ability—resulting in poor classification performance. To address these shortcomings in future work, we propose incorporating depth information fusion or augmenting the training set with background removed object images, and exploring Spatial Pyramid Matching (SPM) to reintroduce spatial structure into the BoVW framework.
5 Interpretation and Comparison of Object Recognition Results for the Two Methods
Our experiments reveal a pronounced performance gap between the two approaches. The CNN method outperforms the traditional CV pipeline by roughly 50% on the critical Categorization and Demonstrator subsets.

The traditional pipeline—detecting keypoints, extracting local descriptors, and classifying via a Bag-of-Visual-Words histogram—vectorizes each image based on dataset-specific features. When the dataset contains highly discriminative keypoints, the model performs well; otherwise, its reliance on those local features becomes a liability. By focusing on corners and high-contrast regions, SIFT struggles to capture large, smooth textured areas, losing the ability to learn and predict those features. Moreover, operating on grayscale images emphasizes edges and reduces background noise but sacrifices important colour information. Finally, converting to a BoW histogram discards all spatial context, leaving only word-occurrence frequencies; the model never truly learns intrinsic object representations, so its accuracy plummets under background interference or when generalization is required[13].
In contrast, a CNN ingests the full image end-to-end and applies hierarchical convolutions and pooling to extract both local edge details and global spatial patterns. Its superior background robustness is evident in the Background subset: the CNN learns object-centric features and suppresses spurious background cues, demonstrating that end-to-end feature learning yields more stable object recognition. These learned features are then passed through fully connected layers for classification—an opaque “black box” process that, unlike the traditional pipeline, sacrifices interpretability for predictive power.
From a training standpoint, CNNs require more epochs and larger datasets to acquire rich feature representations, trading additional computational cost and memory for higher accuracy. Therefore, in scenarios with tight compute constraints—such as edge devices—the traditional CV approach can still be advantageous. However, when a lightweight CNN is feasible, it remains the superior choice.
In summary, for robotic vision applications demanding robust recognition under varied real-world conditions, convolutional neural networks should be the primary approach; but in well controlled environments with limited computational resources, the BoVW-based pipeline offers a simple and interpretable fallback.
6 State-of-the-art in computer vision for robotics
In recent years, the intersection of robotics and computer vision driven by deep learning has made significant strides, giving rise to numerous frontier research directions. In this section, we explore some of these leading-edge techniques.
6.1 Vision Transformers and Architectural Innovations
Within the vanguard of computer-vision research, the emergence of the Vision Transformer (ViT) marks a paradigm shift. Traditional convolutional neural networks (CNNs) have dominated image tasks for years, yet the Transformer’s success in natural-language processing inspired its application to vision. ViT[14] demonstrated that a pure self-attention based model—trained on sufficiently large datasets—can match or even surpass CNNs in image-classification accuracy. By dividing an image into a sequence of patches and applying global self-attention, ViT captures long-range dependencies across the entire image. This approach both simplifies complex convolutional designs and endows the model with a truly global receptive field. Owing to its modularity and scalability, ViT can be deepened and scaled to massive data volumes, opening new avenues for precision gains in classification, detection, and segmentation tasks.
During 2024, much architectural innovation has focused on boosting ViT’s efficiency and tailoring it to specific tasks. A key direction is hierarchical and sparse attention. Early ViT models incurred heavy computational costs as self-attention scales quadratically with token count. At CVPR 2024, Zhang et al. introduced the Less-Attention Vision Transformer (LaViT), which further reduces redundant attention computations[15]. They observe that full self-attention at every layer not only burdens computation but also leads to “attention saturation,” where deeper layers merely re emphasize similar patterns. LaViT divides the Transformer into stages: only the first few layers in each stage compute full attention maps; subsequent layers approximate and reuse these maps via lightweight linear transformations. This design ensures that each stage focuses on necessary attention patterns, cutting compute and avoiding repeated information saturation. LaViT relies almost exclusively on basic matrix multiplications, making it both simple and highly efficient for existing deep-learning frameworks. On ImageNet classification, COCO detection, and ADE20K segmentation, LaViT achieves performance on par with—or superior to— standard ViT, but with substantially lower compute, proving that “less attention” need not sacrifice accuracy.

Beyond backbone optimizations, many innovations address specialized tasks with Vision Transformers. For instance, in semi-supervised semantic segmentation, vanilla ViT may overlook fine-grained details. Addressing this, Hu et al. presented S4Former at CVPR 2024—a Transformer framework tailored for semi-supervised segmentation[16]. S4Former embeds ViT as its backbone within a teacher student paradigm and introduces three key innovations: PatchShuffle perturbations to enhance uncertainty, Patch Adaptive Self-Attention (PASA) to modulate attention at fine scales, and a Negative Class Ranking (NCR) loss to constrain unannotated classes. Experiments on Pascal VOC 2012, COCO, and Cityscapes in semi-supervised settings show that S4Former outperforms prior methods by an average of 4.9 mIoU, setting new state-of-the-art results. Crucially, it retains the Transformer’s simplicity and scalability, integrating seamlessly with existing segmentation pipelines. This underscores that task-driven customizations of ViT can fully leverage its strengths in specialized scenarios.
Overall, Vision Transformer architecture research is thriving: from general–purpose improvements for efficiency and scale (e.g., LaViT) to task-specific designs (e.g., S4Former). Together, these innovations are steering Transformers toward maturity and broader adoption in vision.
When compared to previous methods, these advances have propelled Vision Transformers and their variants to outperform traditional CNNs across many vision tasks. In image classification, ViT now matches or exceeds CNN performance when pretrained on large data. In object detection and instance segmentation, hierarchical Transformers (e.g., Swin Transformer) have become mainstream backbones, boosting detection AP by several points on COCO while maintaining comparable parameter counts and inference speeds to ResNet—delivering both performance and efficiency. Transformers also excel in multi-task learning: their global context modelling enables a single model to output multiple task predictions (e.g., classification + segmentation) from shared representations, surpassing single-task networks that require multi-branch designs. Furthermore, Transformers scale naturally: enormous models like ViT-22B (2.2 billion parameters) continue to push classification performance on JFT-300M data—an almost unimaginable scale for CNNs. In sum, architectural innovations have unlocked the full potential of Vision Transformers, driving a new wave of performance gains and generalization beyond classical convolutional networks.
Nevertheless, these models still face limitations. First, computational and memory costs remain high: even with optimizations like LaViT, self-attention on high-resolution feature maps is expensive, and further reducing complexity without accuracy loss is an open challenge. Second, data dependence persists: lacking the convolutional inductive bias for local patterns, Transformers can overfit when data are scarce. Recent work addresses this by embedding convolutions within Transformers or leveraging synthetic data and stronger augmentations. Third, interpretability demands more study: while CNNs benefit from filter-visualization techniques, attention maps in Transformers do not fully reveal decision rationale, calling for new analysis tools to understand large-scale models’ internal representations. Finally, deploying Transformers in specialized domains (e.g., embedded devices, medical imaging) remains difficult due to their hardware demands and challenges in fine-tuning on small datasets. Encouragingly, the deep-learning community is tackling these issues through approaches like knowledge distillation into compact models and self-supervised pretraining to reduce annotation requirements. It is foreseeable that Vision Transformer architectures will become ever more efficient, robust, and transparent, with deep learning continuing to play a central role in this evolution.
6.2 General Robot Foundation Models (GRFM)
General Robot Foundation Models seek to bring the “large model” paradigm from NLP into robotics by building massive, multimodal models that can serve many tasks and environments. Traditional robotic systems are often tailored to a single task, with limited generalization; by pretraining on vast, diverse datasets, foundation models promise greater flexibility and cross-task transfer. For example, DeepMind’s Gato[17] first demonstrated that a single Transformer can, in a unified architecture, play video games, manipulate robotic arms, and process language—all from one set of shared parameters. Inspired by Gato, researchers now explore unified perception-and-decision models: pretrained on massive multimodal data, they are then adapted to new tasks with only a few examples, achieving true “one-model, many-skills” operation. This shift is driven by the need for future robots to operate in open, unpredictable environments and to handle a wide range of tasks without bespoke pipelines.
State-of-the-art GRFMs typically employ deep Transformer backbones to fuse vision, language, and control signals in an end-to-end fashion. One class of approaches directly trains the model to output low-level action sequences: Google Robotics’ RT-1 and RT-2 use hundreds of thousands of human demonstration videos paired with textual instructions to teach a Transformer to map images and commands into continuous robot control outputs. Another class introduces an intermediate planning layer for better generality: Google’s SayCan and PaLM-E leverage large language models to plan high-level steps, converting perceived scenes and instructions into executable action sequences. By using a language or code “medium” for planning, these methods gain interpretability and easier transfer—e.g., Ahn et al. use a language model to reason about next actions, while Driess et al. embed visual features into PaLM-E’s 562B-parameter model to unify vision, language, and control[18]. Architecturally, GRFMs comprise a pretrained vision encoder (often a ViT), a language encoder (for commands and semantics), and an action decoder (to generate control signals). DeepMind’s latest Gemini model exemplifies this trend, combining huge multimodal Transformers with millions of tokens of context to understand and generate long-horizon action sequences.
Compared to traditional modular pipelines, GRFMs exhibit far stronger cross-task generalization and data-efficient learning. For instance, Google’s One-shot Open Affordance Learning (OOAL)[19] uses a vision-language foundation model to classify object affordances from a single example—using less than 1% of the data required by prior specialized models, yet surpassing their performance. In a complex real-world box pushing task, fine-tuning Gemini on simulated demonstrations enabled zero-shot transfer to a real robot: it not only recovered most of an expert policy’s performance but also showed semantic generalization—handling new objects, multilingual commands, and unseen room layouts. Both RT-2 and Gemini, trained purely in simulation, succeeded zero-shot on real hardware, illustrating the cross-environment and cross-task transfer that is out of reach for traditional reinforcement learning or behavior-cloning approaches. By contrast, single task models often demand extensive additional data and tuning whenever the environment or instructions change; foundation models deliver “one-for-all” capability that lifts both accuracy ceilings and application flexibility.
Yet GRFMs also face significant challenges. First, data scarcity remains critical: unlike internet-scale image and text corpora, real robot interaction data are scarce and costly, limiting model scale[17]. To address this, researchers pool data across institutions and leverage large-scale simulated interactions—e.g., the Proc4Gem initiative uses high-fidelity simulators to “convert compute into data” and augment real datasets. Second, true open-world generalization is still brittle: foundation models may behave unpredictably in extreme, out of-distribution scenarios. Third, high computational and memory demands—billions of parameters and heavy self attention costs—hinder real-time control. Recent work on knowledge distillation and hierarchical decision architectures aims to compress models and reduce inference latency. Finally, safety and reliability concerns arise when deploying such powerful models on physical robots. In sum, while GRFMs mark a leap forward for robotic perception and control, overcoming data, compute, and safety limitations will be key to their future success.
9 Conclusion
This study compared the traditional BoVW+SVM pipeline with the CNN approach on the iCubWorld1.0 and CIFAR 10 datasets, demonstrating that CNNs possess markedly stronger feature representation and generalization capabilities in complex scenarios (novel instances, new demonstrators, and robot viewpoints), whereas BoVW’s performance is constrained by background dependence and the loss of spatial information. By investigating both methods, we have gained deeper insights into object recognition research in robotics and vision. Recent advances suggest that future gains in robotic-vision accuracy and real-time performance can be achieved through multimodal fusion, Vision Transformer architectures, and General Robot Foundation Models.
Reference:
[1] LeCun, Y., Bottou, L., Bengio, Y. & Haffner, P., 1998. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), pp. 2278–2324.
[2] Krizhevsky, A., Sutskever, I. & Hinton, G.E., 2012. ImageNet classification with deep convolutional neural networks. In: Advances in Neural Information Processing Systems (NeurIPS), Lake Tahoe, NV, USA, December 2012, pp.1097–1105.
[3] Fanello, S.R., Ciliberto, C., Santoro, M., Natale, L., Metta, G., Rosasco, L. & Odone, F., 2013. iCub World: Friendly Robots Help Building Good Vision Data-Sets. arXiv:1306.3560.
[4] Krizhevsky, A. & Hinton, G., 2009. Learning Multiple Layers of Features from Tiny Images. Technical report, University of Toronto.
[5] Lin, M., Chen, Q. & Yan, S., 2013. Network In Network. International Conference on Learning Representations (ICLR).
[6] Tan, M. & Le, Q.V., 2019. EfficientNet: Rethinking model scaling for convolutional neural networks. In: International Conference on Machine Learning (ICML), pp. 6105–6114.
[7] Harris, C. & Stephens, M., 1988. A combined corner and edge detector. Alvey Vision Conference, pp. 147–151.
[8] Lowe, D.G., 2004. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 60(2), pp. 91–110.
[9] Arandjelović, R. & Zisserman, A., 2012. Three things everyone should know to improve object retrieval. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, June 2012. IEEE, pp. 2911–2918.
[10] Sivic, J. & Zisserman, A., 2003. Video Google: A text retrieval approach to object matching in videos. In: Proceedings of the Ninth IEEE International Conference on Computer Vision (ICCV), Nice, France, October 2003. IEEE, pp. 1470–1477.
[11] Csurka, G., Dance, C.R., Fan, L., Willamowski, J. & Bray, C., 2004. Visual categorization with bags of keypoints. In: ECCV Workshop on Statistical Learning in Computer Vision.
[12] Hentschel, C. & Sack, H., 2014. Does one size really fit all? Evaluating classifiers in bag-of visual-words classification. In: Proceedings of the 14th International Conference on Knowledge Technologies and Data-driven Business (i KNOW ’14), Graz, Austria, 16–19 September 2014. Article No. 7, pp. 1–8. ACM. doi:10.1145/2637748.2638424
[13] Lazebnik, S., Schmid, C. & Ponce, J., 2006. Beyond bags of features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), New York, NY, USA, June 2006. IEEE, pp. 2169 2178.
[14] Dosovitskiy, A. et al., 2021. An image is worth 16×16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations (ICLR).
[15] Zhang, S., Liu, H., Lin, S. & He, K., 2024. You only need less attention at each stage in vision transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 10 June 2024.
[16] Hu, X., Jiang, L. & Schiele, B., 2024. Training vision transformers for semi-supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4007–4017.
[17] Reed, S. et al., 2022. A generalist agent. arXiv:2205.06175.
[18] Driess, D. et al., 2023. PaLM-E: An embodied multimodal language model. arXiv:2303.03378.
[19] Li, G., Sun, D., Sevilla-Lara, L. & Jampani, V., 2024. One-Shot Open Affordance Learning with Foundation Models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 16–20 June 2024, pp. 3086–3095.


留言