
A Simple Demo of Continual Learning of LLMs
- Apr 25, 2024
- 3 min read
Updated: Nov 12, 2025
I Introduction
Background, Objective, and Challenges
Background
Large Language Model (LLM) has rapid development in solving various problems. However, frequent re-training LLMs is not amenable due to high training costs. Hence, continual learning is required to enhance the capabilities of LLMs.
Objective data
Automatically crawl new data from the website to fine-tune the model.
Function
We hope the LLM have the conversation skills and a certain ability to remember past conversations.
Feedback
A feedback loop can be applied to enhance its overall abilities and reduce catastrophic forgetting.
Challenges
OpenAI API Challenge: It was deactivated. Solution: Use open source model Llama.
Crawling data Challenge: Difficulty in crawling Quora’s data. Solution: Use API for help.
Training data format Challenge: Question and answer format cannot realize the dialogue function. Solution: Use chat template formate for causal language modeling.
Perplexity Challenge: The existing code reload model every time when evaluated, which is time-consuming. Solution: Rewrote code for loading model once.

II Implementation Data Source
Raw Data: We crawled the questions and answers from the technology sector https://www.quora.com/topic/Technology. Pre-processed data: First, we filtered the questions without answers. Then, we transformed the left Q&A pairs into chat mode, where “user”ask questions and “assistant” provide answers. Training Data
Resources Downloaded Quora Question and answer datasets from Hugging_face:
The first 5 of them were used for training.
Features question, answer_text, upvotes, comment_count, answer_shared, answer_date

Code
Data Processing Loop
Crawl data from quora.com by API and output in .json formt
prepare_data.py Convert raw data into the format we needed.
summarize.py Use LLMs to summarize the raw text into high quality dataset.

Training and Evaluation Loop
cl_trainer.py Feed new datasets to the model continually.
eval_metrics.py Perplexity is used to evaluate the performance of our model.
demo.py A simple demo to chat with the trained models.
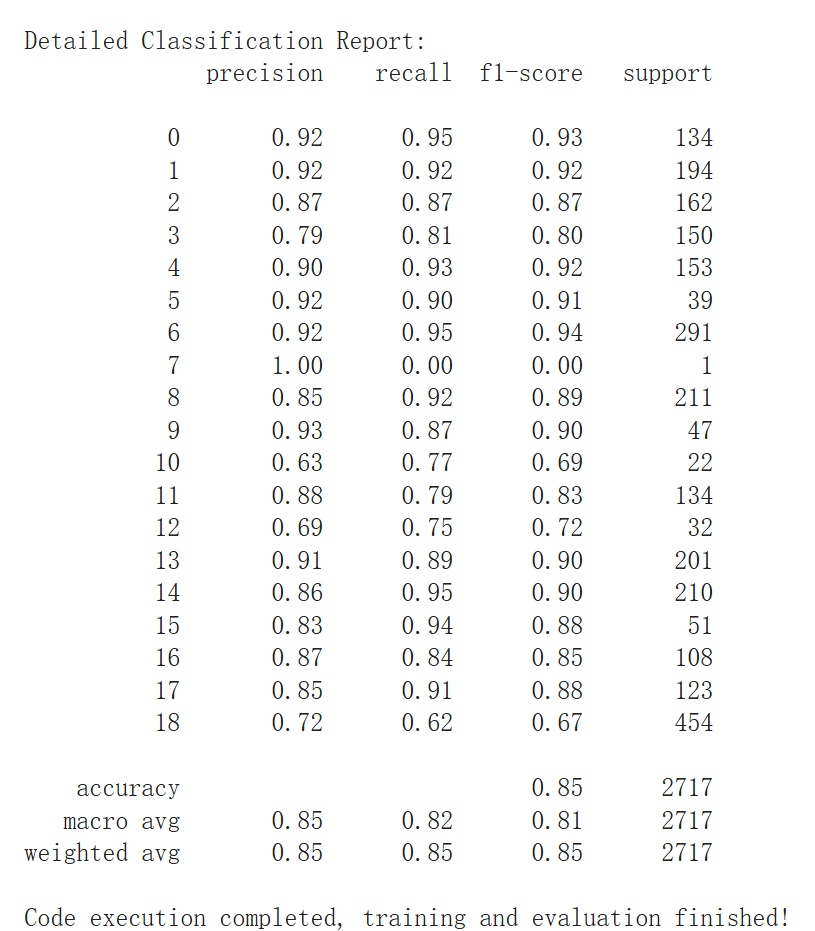
III Results
Results and evaluation
Train We use GPT-2 as our pre-trained model. (total parameter: 124M)
Train Device: RTX 4090
To study to model’s ability to continually learn new knowledge, we choose 5 parts from the dataset “quora_qa”and sequentially feed them to the model.
We use LoRA adapter as trainable parameters and merge the adapter only after training the final stream.
Each stream is trained for 3 epochs before the next stream arrives.

Evaluation
Perplexity

where wₙ represents the n-th character of the input text, and N is the length of the input text.
470.7 | |||||
420.4 | 434.1 | ||||
Data Stream | 230.7 | 233.7 | 237.3 | ||
374.3 | 453.1 | 441.0 | 460.0 | ||
185.7 | 178.1 | 196.1 | 202.7 | 205.3 | |
Model Generation |
High-Level Insight
Continual Acquiring Knowledge
By training LLMs with sequential data stream using LoRA update technique, the model is able to continually acquiring new knowledge.
Scale Matters
The generation performance is limited by the scale of the model (GPT-2). In order to fully exploit the advantage of scaling law, larger model is needed.
IV Conclusion
Conclusion and future work
Future Direction
memory augmentation This enhancement could potentially enable the LLM to retain and utilize past interactions more effectively
Pre-training Methods DAP-training incorporates a novel soft-masking mechanism and a new proxy to preserve general knowledge, effectively integrating new and existing knowledge while preventing catastrophic forgetting.
Against Catastrophic Forgetting MemoryBank allows the LLM to mimic human memory, adapting to user personalities and selectively reinforcing or forgetting details over time.
References
Data:
Model:
Framework/package:
PyTorch, peft, transformers, crawlbase
Literature:
Continual Learning for Large Language Models: A Survey. https://doi.org/10.48550/arxiv.2402.01364
Towards Continual Knowledge Learning of Language Models: https://arxiv.org/abs/2110.03215
Continual Pre-Training Mitigates Forgetting in Language and Vision: https://arxiv.org/abs/2205.09357
Continual Training of Language Models for Few-Shot Learning: https://arxiv.org/abs/2210.05549
MemoryBank: Enhancing Large Language Models with Long-Term Memory: https://arxiv.org/pdf/2305.10250.pdf


Comments